
Is Your Analytics Data Single Use or Multipurpose?

I just finished reading an article on data pipelines and how this approach to accessing and sharing data will improve and simplify data access for analytics developers and users. The key tenets of the data pipeline approach include simplifying data access by ensuring that pipelines are visible and reusable, and delivering data that is discoverable, shareable, and usable. The article covered the details of placing the data on a central platform to make it available, using open source utilities to simplify construction, transforming the data to make the data usable, and cataloging the data to make it discoverable. The idea is that data should be multipurpose, not single use. Building reusable code that delivers source data sets that are easily identified and used has been around since the 1960’s. It’s a great idea and even simpler now with today’s technologies and methods than it was 50+ years ago.
The idea of reusable components is a concept that has been in place in the automobile industry for many years. Why create custom nuts, bolts, radios, engines, and transmissions if the function they provide isn’t unique and doesn’t differentiate the overall product? That’s why GM, Ford and others have standard parts that are used across their numerous products. The parts, their capabilities, and specifications are documented and easily referenceable to ensure they are used as much as possible. They have lots of custom parts too; those are the ones that differentiate the individual products (exterior body panels, bumpers, windshields, seats, etc.) Designing products that maximize the use of standard parts dramatically reduces the cost and expedites delivery. Knowing which parts to standardize is based on identifying common functions (and needs) across products.
It’s fairly common for an analytics team to be self-contained and focused on an individual set of business needs. The team builds software to ingest, process, and load data into a database to suit their specific requirements. While there might be hundreds of data elements that are processed, only those elements specific to the business purpose will be checked for accuracy and fixed. There’s no attention to delivering data that can be used by other project teams, because the team isn’t measured or rewarded on sharing data; they’re measured against a specific set of business value criteria (functionality, delivery time, cost, etc.)
This creates the situation where multiple development teams ingest, process, and load data from the same sources for their individual projects. They all function independently and aren’t aware of the other teams’ activities. I worked with a client that had 14 different development teams each loading data from the same source system. They didn’t know what each other was doing nor were they aware that there was any overlap. While data pipelining technology may have helped this client, the real challenge wasn’t tooling, it was the lack of a methodology focused on sharing and reuse. Every data development effort was a custom endeavor; there was no economies-of-scale or reuse. Each project team built single use data, not multipurpose data that could be shared and reused.
The approach to using standard and reusable parts requires a long-term view of product development costs. The initial cost for building standard components is expensive, but it’s justified in reduced delivery costs through reuse in future projects. The key is understanding which components should be built for reuse and which parts are unique and are necessary for differentiation. Any organization that takes this approach invests in staff resources that focus on identifying standard components and reviewing designs to ensure the maximum use of standard parts. Success is also dependent on communicating across the numerous teams to ensure they are aware of the latest standard parts, methods, and practices.
The building of reusable code and reusable data requires a long-term view and an understanding of the processing functions and data that can be shared across projects. This approach isn’t dependent on specific tooling; it’s about having the development methods and staff focused on ensuring that reuse is a mandatory requirement. Data Pipelining is indeed a powerful approach; however, without the necessary development methods and practices, the creation of reusable code and data won’t occur.
There’s nearly universal agreement within most companies that all development efforts should generate reusable artifacts. Unfortunately, the reality is that this concept gets more lip service than attention. While most companies have lots of tools available to support the sharing of code and data, few companies invest in their staff members to support such techniques. It’s rare that I’ve seen any organization identify staff members that are tasked with establishing data standards and require the review of development artifacts to ensure the sharing and reuse of code and data. Even fewer organizations have the data development methods that ensure collaboration and sharing occurs across teams. Everyone has collaboration tools, but the methods and practices to utilize them to support reuse isn’t promoted (and often doesn’t even exist).
The automobile industry learned that building cars in a custom manner wasn’t cost effective; using standard parts became a necessity. While most business and technology executives agree that reusable code and shared data is a necessity, few realize that their analytics teams address each data project in a custom, build-from-scratch manner. I wonder if the executives responsible for data and analytics have ever considered measuring (or analyzing) how much data reuse actually occurs?
Is Your IT Team Prepared for a Data-Driven Business?

I wrote last time about the challenges that companies have in their transition to becoming data driven. Much has been written about the necessity of the business audience needing to embrace change. I thought I’d spend a few words discussing the other participant in a company’s data-driven transition: the Information Technology (IT) organization.
One of the issues that folks rarely discuss is that many IT organizations haven’t positioned themselves to support a data-driven culture. While most have spent a fortune on technology, the focus is always about installing hardware, building platforms, acquiring software, developing architectures, and delivering applications. IT environments focus on streamlining the construction and maintenance of systems and applications. While this is important, that’s only half the solution for a data-driven organization. A data-driven culture (or philosophy) requires that all of a company’s business data is accessible and usable. Data has to be packaged for sharing and use.
Part of the journey to becoming data-driven is ensuring that there’s a cultural adjustment within IT to support the delivery of applications and data. It’s not just about dropping data files onto servers for users to copy. It’s about investing in the necessary methods and practices to ensure that data is available and usable (without requiring lots of additional custom development).
Some of the indicators that your IT organization isn’t prepared or willing to be data-driven include
- There’s no identified Single Version Of Truth (SVOT).
There should be one place where the data is stored. While this is obvious, the lack of a single agreed to data location creates the opportunity to have multiple data repositories and multiple (and conflicting) sets of numbers. Time is wasted disputing accuracy instead of being focused on business analysis and decision making.
- Data sharing is a courtesy, not an obligation.
How can a company be data driven if finding and accessing data requires multiple meetings and multiple approvals for every request? If we’re going to run the business by the numbers, we can’t waste time begging or pleading for data from the various system owners. Every application system should have two responsibilities: processing transactions and sharing data.
- There’s no investment in data reuse.
The whole idea of technology reuse has been a foundational philosophy for IT for more than 20 years: build once, use often. While most IT organizations have embraced this for application development, it’s often overlooked for data. Unfortunately, data sharing activities are often built as a one-off, custom endeavor. Most IT teams manage 100’s or 1000’s of file extract programs (for a single system) and have no standard for moving data packets between applications. There’s no reuse; every new request gets their own extract or service/connection.
- Data accuracy and data correction is not a responsibility
Most IT organizations have invested in data quality tools to address data correction and accuracy, but few ever use them. It’s surprising to me that any shop allows new development to occur without requiring the inclusion of a data inspection and correction process. How can a business person become data driven if they can’t trust the data? How can you expect them to change if the IT hasn’t invested in fixing the data when it’s created (or at least shared)?
It’s important to consider that enabling IT to support a data-driven transition isn’t realistic without investment. You can’t expect staff members that are busy with their existing duties to absorb additional responsibilities (after all, most IT organizations have a backlog). If a company wants to transition to a data-driven philosophy, you have to allow the team members to learn new skills to support the additional activities. And, there needs to be staff members available to do the work.
There’s only one reason to transition to being a data-driven organization; it’s about more profit, more productivity, and more business success. Consequently, there should be funds available to allow IT to support the transition.
Your Company’s Problem with Data may be Fear

I just read this article by Ethan Knox, “Is Your Company Too Dumb to be Data Driven” and was intrigued to read what many people have discussed for years. I’ve spent nearly half my career helping clients make the transition from running the business by tribal knowledge and gut instinct to running the business by facts and numbers. It’s a hard transition. One that takes vision, motivation, discipline, and courage to change. It also takes a willingness to learn something new.
While this article covers a lot of ground, I wanted to comment on one of points made in the article: the mistake of “build it and they will come”. This occurs when an organization is enthusiastic about data and decides to build a data warehouse (or data lake) and load it with all the data from the company’s core application systems (sales, finance, operations, etc.) The whole business case depends on the users flocking to the system, using new business intelligence or reporting tools, and uncovering numerous high value business insights. All too often, the results reflect a large monolithic data platform that contains lots of content but hasn’t been designed to support analysis or decision making by the masses.
There are numerous problems with this approach – and the path to data and analytics enlightenment is littered with mistakes where companies took this approach. Don’t assume that successful companies that have embraced data and analytics didn’t make this mistake (it’s a very common mistake). Successful companies were those that were willing to learn from their mistakes – and have a culture where new project efforts are carefully scoped to allow mistakes, learning, and evolution. It’s not that they’re brilliant; successful companies understand that transitioning to being data driven company requires building knowledge. And, the process of learning takes time, includes mistakes, requires self-analysis, and must be managed and mentored carefully. They design their projects assuming mistakes and surprises occur, so they fail fast and demand continual measurement and corrective action. It’s not about the methodology or development approach. A fail-fast philosophy can work with any type of development methodology (agile, iterative, waterfall). The path to data enlightenment will include lots of mistakes.
Do you remember high school math? When you were presented with a new concept, you were given homework that allowed you to learn, gain experience, and understand the concept through the act of “doing”. Homework was often graded based on effort, not accuracy (if you did it, you got credit, whether or not it was correct). Where is it written that (upon graduation) learning something new wouldn’t require the act of “doing” and making mistakes to gain enlightenment? By the way, who has ever succeeded without making mistakes?
The point the article frequently references it that business engagement is critical. It’s not about the users participating a few times (requirements gathering and user acceptance testing); it’s about users being engaged to review results and participate in the measurement and corrective action. It’s about evolving from a culture where the relationship is customer/ provider to a team where everyone succeeds or fails based on business measurement.
It’s not that a company is too dumb to succeed with data; it’s that they’re often too fearful of mistakes to succeed. And in the world of imperfect data, exploding data volumes, frequent technology changes, and a competitive business environment, mistakes are an indication of learning. Failure isn’t a reflection of mistakes, it’s a reflection of poor planning, lack of measurement, and an inability to take corrective action.
Data Sharing is a Production Need

The concept of “Production” in the area of Information Technology is well understood. It means something (usually an application or system) is ready to support business processing in a reliable manner. Production environments undergo thorough testing to ensure that there’s minimal likelihood of a circumstance where business activities are affected. The Production label isn’t thrown around recklessly; if a system is characterized as Production, there are lots of business people dependent on those systems to get their job done.
In order to support Production, most IT organizations have devoted resources focused solely on maintaining Production systems to ensure that any problem is addressed quickly. When user applications are characterized as Production, there’s special processes (and manpower) in place to address installation, training, setup, and ongoing support. Production systems are business critical to a company.
One of the challenges in the world of data is that most IT organizations view their managed assets as storage, systems, and applications. Data is treated not as an asset, but as a byproduct of an application. Data storage is managed based on application needs (online storage, archival, backup, etc.) and data sharing is handled as a one-off activity. This might have made sense in the 70’s and 80’s when most systems were vendor specific and sharing data was rare; however, in today’s world of analytics and data-driven decision making, data sharing has become a necessity. We know that every time data is created, there are likely 10-12 business activities requiring access to that data.
Data sharing is a production business need.
Unfortunately, the concept of data sharing in most companies is a handled as a one-off, custom event. Getting a copy of data often requires tribal knowledge, relationships, and a personal request. While there’s no arguing that many companies have data warehouses (or data marts, data lakes, etc.), adding new data to those systems is where I’m focused. Adding new data or integrating 3rd party content into a report takes a long time because data sharing is always an afterthought.
Think I’m exaggerating or incorrect? Ask yourself the following questions…
- Is there a documented list of data sources, their content, and a description of the content at your company?
- Do your source systems generate standard extracts, or do they generate 100s (or 1000’s) of nightly files that have been custom built to support data sharing?
- How long does it take to get a copy of data (that isn’t already loaded on the data warehouse)?
- Is there anyone to contact if you want to get a new copy of data?
- Is anyone responsible for ensuring that the data feeds (or extracts) that currently exist are monitored and maintained?
While most IT organizations have focused their code development efforts on reuse, economies-of-scale, and reliability, they haven’t focused their data development efforts in that manner. And one of the most visible challenges is that many IT organizations don’t have a funding model to support data development and data sharing as a separate discipline. They’re focused on building and delivering applications, not building and delivering data. Supporting data sharing as a production business need means adjusting IT responsibilities and priorities to reflect data sharing as a responsibility. This means making sure there are standard extracts (or data interfaces) that everyone can access, data catalogs available containing source system information, and staff resources devoted to sharing and supporting data in a scalable, reliable, and cost-efficient manner. It’s about having an efficient data supply chain to share data within your company. It’s because data sharing is a production business need.
Or, you could continue building everything in a one-off custom manner.
Do You Treat Data as an Asset?

Like many of you, I’m a big believer that data is a valuable business asset. Most business leaders understand the value of data and are prepared to make decisions, adjust their direction, or consider new ideas if the data exists to support the idea. However, while most folks agree that data is valuable, few have really changed their company’s culture or behavior when it comes to treating data as an asset.
The reality is that most corporate data is not treated as an asset. In fact, most company’s data management practices are rooted in methods and practices that are more than 30 years old. Treating data as a business asset is more than investing in storage and data transformation tools. Treating data like a valuable asset means managing, fixing, maintaining content to ensure it’s ready and reliable to support business activities. If you disagree, let’s take a look at how companies treat other valuable business assets.
Consider a well understood asset that exists within numerous companies: the automobile fleet. Companies that invest in automobile fleets do so because the productivity of their team members depends on having this reliable business tool. Automobile fleets exist because staff members require reliable transportation to fulfill their job responsibilities.
The company identifies and tracks the physical cars. They assign cars to individuals, and there’s a slew of rules and responsibilities associated with their use. Preventative maintenance and repairs are handled regularly to maintain the car’s value, reliability and readiness for use. Depending on the size of the fleet, the company may have staff members (equipped with the necessary tools) to handle the ongoing maintenance. The cars are also inspected on a regular basis to ensure that any problems are identified and resolved (again, to maintain its useful life and reliability). There is also criteria for disposing of cars at their end-of-life (which is predetermined based on when the costs and liabilities exceed their value). These activities aren’t discretionary, they are necessary to protect the company’s investment in their valuable business assets.
Now, consider applying the same set of concepts to your company’s data assets.
- Is someone responsible for tracking the data assets? (Is there a list of data sources? Are they updated/maintained? Is the list published?)
- Are the responsibilities and rules for data usage identified and documented? (Does this occur for all data assets, or is it specific to individual platforms?)
- Is there a team that is responsible for monitoring and inspecting data for problems? (Are they equipped with the necessary tools to accomplish such a task?)
- Is there anyone responsible for maintaining and/or fixing inaccurate data?
- Are there details reflecting the end-of-life criteria for your data assets when the liability and costs of the data exceed their value?
If you answered no to any these questions, it’s likely that your company views data as a tool or a commodity, but not a valuable business asset.
So, what do you do?
I certainly wouldn’t grab this list and run around the office claiming that the company isn’t treating data as an asset. Nor, would I suggest that you state that your company likely spends more money maintaining their automobile fleet then its business data. (I once accused a company of spending more on landscaping than data management. It wasn’t well received).
Instead, raise the idea of data investment as a means to increase the value and usefulness of data within the company. Conduct an informal survey to a handful of business users and ask them the time they lose looking for their data. Ask your ETL developers to estimate the time they spend fixing broken data, instead of their core job responsibilities. You’ll find the staff time lost because data isn’t managed and maintained as a business asset vastly exceeds the investment in preventative maintenance, tools, and repairs. You have to educate people about a problem before you can expect them to act to resolve the problem.
And if all else fails, find out how much your company spends on its automobile fleet (per user) and compare it to the non-existent resources spent maintaining and fixing your company’s other valuable business asset.
Data Strategy Component: Govern
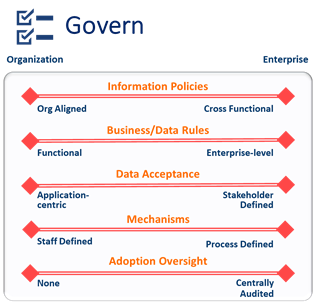 This blog is the final installment in a series focused on reviewing the individual Components of a Data Strategy. This edition discusses the component Govern and the details associated with supporting a Data Governance initiative as part of an overall Data Strategy.
This blog is the final installment in a series focused on reviewing the individual Components of a Data Strategy. This edition discusses the component Govern and the details associated with supporting a Data Governance initiative as part of an overall Data Strategy.
The definition of Govern is:
“Establishing, communicating and monitoring information practices to ensure effective data sharing, usage, and protection”
As you’re likely aware, Data Governance is about establishing (and following) policies, rules, and all of the associated rigor necessary to ensure that data is usable, sharable, and that all of the associated business and legal details are respected. Data Governance exists because data sharing and usage is necessary for decision making. And, the reason that Data Governance is necessary is because the data is often being used for a purpose outside of why it was collected.
I’ve identified 5 facets about Data Governance to consider when developing your Data Strategy. As a reminder (from the initial Data Strategy Component blog), each facet should be considered individually. And because your Data Strategy goals will focus on future aspirational goals as well as current needs, you’ll likely want to consider different options for each. Each facet can target a small organization’s issues or expand to focus on a large company’s diverse needs.
Information Policies
Information policies are high level information-oriented objectives that your company (or organization, or “governing body”) identify. Information policies act as boundaries or guard rails to guide all of the detailed (and often tactical) rules to identify required and acceptable data-oriented behavior. To offer context, some examples of the information policies that I’ve seen include
-
- “All customer data will be protected from unauthorized use”.
- “User data access should be limited to ‘systems of record’(when available)”.
- “All data shipped into and out of the company must be processed by the IT Data Onboarding team”.
It’s very common for Data Governance initiatives to begin with focusing on formalizing and communicating a company’s information policies.
Business Data Rules
Rules are specific lower-level details that explain what a data user (or developer) is and isn’t allowed to do. Business data rules (also referred to as “business rules”) can be categorized into one of four types:
-
- These are the “things” that represent the business details that we measure, track, and analyze. (e.g. a customer, a purchase, a product).
- The details that describe the terms and related details about a business (e.g. The customer purchases a product, Products are sold at a store location).
- These are the details associated with the various items and actions within a company (e.g. The company can only sell a product that is in inventory).
- The distillation or generation of new rules based on other rules. (e.g. Rule: A product can be purchased or returned by a customer. Derivation: A product cannot be returned unless it was purchased from the company).
While the implementation of rules is often the domain of a data administration (or a logical data modeling) team, data governance is often responsible for establishing and managing the process for introducing, communicating, and updating rules.
Data Acceptance
The term quality is often referred to as “conformance to requirements”. Data Acceptance is a similar concept: the details (or rules) and process applied against data to ensure it is suitable for the use intended. The premise of data acceptance is identifying the minimum details necessary to ensure that data can be used or processed support the associated business activities. Some examples of data acceptance criteria include
-
- All data values must be non-null.
- All fields within a record must reflect a value within a defined range of values for that field (or business term).
- The product’s price must be a numeric value that is non-zero and non-negative.
- All addresses must be valid mailable addresses.
In order to correct, standardize, or cleanse data, data acceptance for a specific business value (or term) must be identified.
Mechanism
A Data Governance Mechanism is the method (or process) to identify a new rule, process, or detail to support Data Governance. The components of a mechanisms may include the process definition (or flow), the actors, and their decision rights.
This is an area where many Data Governance initiatives fail. While most Governance teams are very good in building new policies, rules, processes, and the associated rigor, they often forget to establish the mechanisms to allow all of the Governance details to be managed, maintained, and updated. This is critically important because as an organization evolves and matures with Data Governance, it may outgrow many of the initial rules and practices. Establishing a set of mechanisms to support modifying and updating existing rules and practices is important to supporting the growth and evolution of a Data Governance environment
Adoption Oversight
The strength and success of Data Governance shouldn’t be measured by the quantity of rules or policies. The success of Data Governance is reflected by the adoption of the rules and processes that are established. Consequently, it’s important for the Data Governance team to continually measure and report adoption levels to ensure the Data Governance details are applied and followed. And where they challenges in adoption, mechanisms exist to allow stakeholders to adjust and update the various aspects of Data Governance to support the needs of the business and the users.
Data Governance will always be a polarizing concept. Whether introduced as part of a development methodology, included within a new data initiative, required to address a business compliance need, or positioned within a Data Strategy, Data Governance is always going to ruffle feathers.
Why?
Because folks are busy and they don’t want to be told that they need to have their work reviewed, modified, or approved. Data Governance is an approach (and arguably a method, practice, and process) to ensure that data usage and sharing aligns with policy, business rules, and the law. Data Governance is the “rules of the road” for data.
Data Strategy Component: Assemble
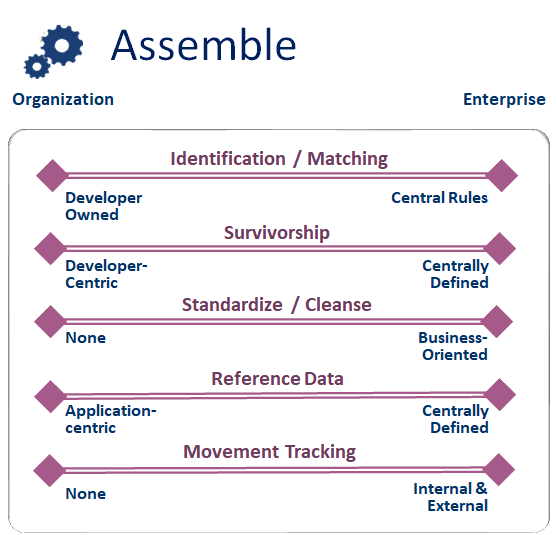
This blog is 4th in a series focused on reviewing the individual Components of a Data Strategy. This edition discusses the component Assemble and the numerous details involved with sourcing, cleansing, standardizing, preparing, integrating, and moving the data to make it ready to use.
The definition of Assemble is:
“Cleansing, standardizing, combining, and moving data residing in multiple locations and producing a unified view”
In the Data Strategy context, Assemble includes all of the activities required to transform data from its host-oriented application context to one that is “ready to use” and understandable by other systems, applications, and users.
Most data used within our companies is generated from the applications that run the company (point-of-sale, inventory management, HR systems, accounting) . While these applications generate lots of data, their focus is on executing specific business functions; they don’t exist to provide data to other systems. Consequently, the data that is generated is “raw” in form; the data reflects the specific aspects of the application (or system of origin). This often means that the data hasn’t been standardized, cleansed, or even checked for accuracy. Assemble is all of the work necessary to convert data from a “raw” state to one that is ready for business usage.
I’ve identified 5 facets to consider when developing your Data Strategy that are commonly employed to make data “ready to use”. As a reminder (from the initial Data Strategy Component blog), each facet should be considered individually. And because your Data Strategy goals will focus on future aspirational goals as well as current needs, you’ll likely want to consider different options for each. Each facet can target a small organization’s issues or expand to focus on a large company’s diverse needs.
Identification and Matching
Data integration is one of the most prevalent data activities occurring within a company; it’s a basic activity employed by developers and users alike. In order to integrate data from multiple sources, it’s necessary to determine the identification values (or keys) from each source (e.g. the employee id in an employee list, the part number in a parts list). The idea of matching is aligning data from different sources with the same identification values. While numeric values are easy to identify and match (using the “=” operator), character-based values can be more complex (due to spelling irregularities, synonyms, and mistakes).
Even though it’s highly tactical, Identification and matching is important to consider within a Data Strategy to ensure that data integration is processed consistently. And one of the (main) reasons that data variances continue to exist within companies (despite their investments in platforms, tools, and repositories) is because the need for standardized Identification and Matching has not been addressed.
Survivorship
Survivorship is a pretty basic concept: the selection of the values to retain (or survive) from the different sources that are merged. Survivorship rules are often unique for each data integration process and typically determined by the developer. In the context of a data strategy, it’s important to identify the “systems of reference” because the identification of these systems provide clarity to developers and users to understand which data elements to retain when integrating data from multiple systems.
Standardize / Cleanse
The premise of data standardization and cleansing is to identify inaccurate data and correct and reformat the data to match the requirements (or the defined standards) for a specific business element. This is likely the single most beneficial process to improve the business value (and the usability) of data. The most common challenge to data standardization and cleansing is that it can be difficult to define the requirements. The other challenge is that most users aren’t aware that their company’s data isn’t standardized and cleansed as a matter of practice. Even though most companies have multiple tools to cleanup addresses, standardize descriptive details, and check the accuracy of values, the use of these tools is not common.
Reference Data
Wikipedia defines reference data as data that is used to classify or categorize other data. In the context of a data strategy, reference data is important because it ensures the consistency of data usage and meaning across different systems and business areas. Successful reference data means that details are consistently identified, represented, and formatted the same way across all aspects of the company (if the color of a widget is “RED”, then the value is represented as “RED” everywhere – not “R” in product information system, 0xFF0000 in inventory system, and 0xED2939 in product catalog). A Reference Data initiative is often aligned with a company’s data strategy initiative because of its impact to data sharing and reuse.
Movement Tracking
The idea of movement is to record the different systems that a data element touches as it travels (and is processed) after the data element is created. Movement tracking (or data lineage) is quite important when the validity and accuracy of a particular data value is questioned. And in the current era of heightened consumer data privacy and protection, the need for data lineage and tracking of consumer data within a company is becoming a requirement (and it’s the law in California and the European Union).
The dramatic increase in the quantity and diversity of data sources within most companies over the past few years has challenged even the most technology advanced organizations. It’s not uncommon to find one of the most visible areas of user frustration to be associated with accessing new (or additional) data sources. Much of this frustration occurs because of the challenge in sourcing, integrating, cleansing, and standardizing new data content to be shared with users. As is the case with all of the other components, the details are easy to understand, but complex to implement. A company’s data strategy has to evolve and change when data sharing becomes a production business requirement and users want data that is “ready to use”.
Data Strategy Component: Store
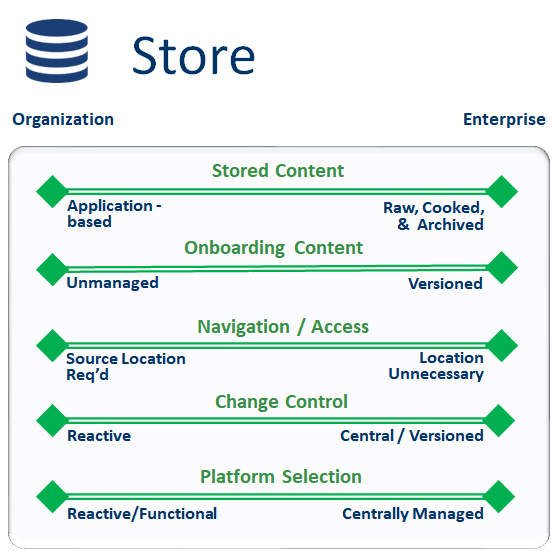
This blog is 3rd in a series focused on reviewing the individual Components of a Data Strategy. This edition discusses storage and the details involved with determining the most effective method for persisting data and ensuring that it can be found, accessed, and used.
The definition of Store is:
“Persisting data in a structure and location that supports access and processing across the user audience”
Information storage is one of the most basic responsibilities of an Information Technology organization – and it’s an activity that nearly every company addresses effectively. On its surface, the idea of storage seems like a pretty simple concept: setup and install servers with sufficient storage (disk, solid state, optical, etc.) to persist and retain information for a defined period of time. And while this description is accurate, it’s incomplete. In the era of exploding data volumes, unstructured content, 3rd party data, and need to share information, the actual media that contains the content is the tip of the iceberg. The challenges with this Data Strategy Component are addressing all of the associated details involved with ensuring the data is accessible and usable.
In most companies, the options of where data is stored is overwhelming. The core application systems use special technology to provide fast, highly reliable, and efficiently positioned data. The analytics world has numerous databases and platforms to support the loading and analyzing of a seemingly endless variety of content that spans the entirety of a company’s digital existence. Most team members’ desktops can expand their storage to handle 4 terabytes of data for less than a $100. And there’s the cloud options that provide a nearly endless set of alternatives for small and large data content and processing needs. Unfortunately, this high degree of flexibility has introduced a whole slew of challenges when it comes to managing storage: finding the data, determining if the data has changed, navigating and accessing the details, and knowing the origin (or lineage).
I’ve identified 5 facets to consider when developing your Data Strategy and analyzing data storage and retention. As a reminder (from the initial Data Strategy Component blog), each facet should be considered individually. And because your Data Strategy goals will focus on future aspirational goals as well as current needs, you’ll likely to want to consider the different options for each. Each facet can target a small organization’s issues or expand to focus on a large company’s diverse needs.
Stored Content
The most basic facet of storing data is to identify the type of content that will be stored: raw application data, rationalized business content, or something in between. It’s fairly common for companies to store the raw data from an application system (frequently in a data lake) as well as the cooked data (in a data warehouse). The concept of “cooked” data refers to data that’s been standardized, cleaned, and stored in a state that’s “ready-to-use”. It’s likely that your company also has numerous backup copies of the various images to support the recovery from a catastrophic situation. The rigor of the content is independent of the platform where the data is stored.
Onboarding Content
There’s a bunch of work involved with acquiring and gathering data to store it and make it “ready-to-use”. One of the challenges of having a diverse set of data from numerous sources is tracking what you have and knowing where it’s located. Any type of inventory requires that the “stuff” get tracked from the moment of creation. The idea of Onboarding Content is to centrally manage and track all data that is coming into and distributed within your company (in much the same way that a receiving area works within a warehouse). The core benefit of establishing Onboarding as a single point of data reception (or gathering) is that it ensures that there’s a single place to record (and track) all acquired data. The secondary set of benefits are significant: it prevents unnecessary duplicate acquisition, provides a starting point for cataloging, and allows for the checking and acceptance of any purchased content (which is always an issue).
Navigation / Access
All too often, business people know the data want and may even know where the data is located; unfortunately, the problem is that they don’t know how to navigate and access the data where it’s stored (or created). To be fair, most operational application systems were never designed for data sharing; they were configured to process data and support a specific set of business functions. Consequently, accessing the data requires a significant level of system knowledge to navigate the associated repository to retrieve the data. In developing a Data Strategy, it’s important to identify the skills, tools, and knowledge required for a user to access the data they require. Will you require someone to have application interface and programming skills? SQL skills and relational database knowledge? Or, spreadsheet skills to access a flat file, or some other variation?
Change Control
Change control is a very simple concept: plan and schedule maintenance activities, identify outages, and communicate those details to everyone. This is something that most technologists understand. In fact, most Information Technology organizations do a great job of production change control for their application environments. Unfortunately, few if any organizations have implemented data change control. The concept for data is just as simple: plan and schedule maintenance activities, identify outages (data corruption, load problems, etc.), and communicate those details to everyone. If you’re going to focus any energy on a data strategy, data change control should be considered in the top 5 items to be included as a goal and objective.
Platform Access
As I’ve already mentioned, most companies have lots of different options for housing data. Unfortunately, the criteria for determining the actual resting place for data often comes down to convenience and availability. While many companies have architecture standards and recommendations for where applications and data are positioned, all too often the selection is based on either programmer convenience or resource availability. The point of this area isn’t to argue what the selection criteria are, but to identify them based on core strategic (and business operation) priorities.
In your Data Strategy effort, you may find the need to include other facets in your analysis. Some of the additional details that I’ve used in the past include metadata, security, retention, lineage, and archive access. While simple in concept, this particular component continues to evolve and expand as the need for data access and sharing grows within the business world.
Data Strategy Component: Provision
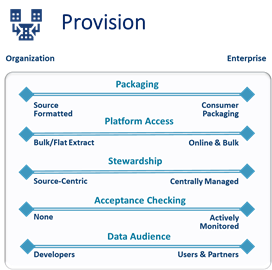
This blog is the 2nd in a series focused on reviewing the individual Components of a Data Strategy. This edition discusses the concept of data provisioning and the various details of making data sharable.
The definition of Provision is:
“Supplying data in a sharable form while respecting all rules and access guidelines”
One of the biggest frustrations that I have in the world of data is that few organizations have established data sharing as a responsibility. Even fewer have setup the data to be ready to share and use by others. It’s not uncommon for a database programmer or report developer to have to retrieve data from a dozen different systems to obtain the data they need. And, the data arrives in different formats and files that change regularly. This lack of consistency generates large ongoing maintenance costs and requires an inordinate amount of developer time to re-transform, prepare, fix data to be used (numerous studies have found that ongoing source data maintenance can take as much of 50% of the database developers time after the initial programming effort is completed).
Should a user have to know the details (or idiosyncrasies) of the application system that created the data to use the data? (That’s like expecting someone to understand the farming of tomatoes and manufacturing process of ketchup in order to be able to put ketchup on their hamburger). The idea of Provision is to establish the necessary rigor to simplify the sharing of data.
I’ve identified 5 of the most common facets of data sharing in the illustration above – there are others. As a reminder (from last week’s blog), each facet should be considered individually. And because your Data Strategy goals will focus on future aspirational goals as well as current needs, you’ll likely to want to review the different options for each facet. Each facet can target a small organization’s issues or expand to address a diverse enterprise’s needs.
Packaging
This is the most obvious aspect of provisioning: structuring and formatting the data in a clear and understandable manner to the data consumer. All too often data is packaged at the convenience of the developer instead of the convenience of the user. So, instead of sharing data as a backup file generated by an application utility in a proprietary (or binary) format, the data should be formatted so every field is labeled and formatted (text, XML) for a non-technical user to access using easily available tools. The data should also be accompanied with metadata to simplify access.
Platform Access
This facet works with Packaging and addresses the details associated with the data container. Data can be shared via a file, a database table, an API, or one of several other methods. While sharing data in a programmer generated file is better than nothing, a more effective approach would be to deliver data in a well-known file format (such as Excel) or within a table contained in an easily accessible database (e.g. data lake or data warehouse).
Stewardship
Source data stewardship is critical in the sharing of data. In this context, a Source Data Steward is someone that is responsible for supporting and maintaining the shared data content (there several different types of data stewards). In some companies, there’s a data steward responsible for the data originating from an individual source system. Some companies (focused on sharing enterprise-level content) have positioned data stewards to support individual subject areas. Regardless of the model used, the data steward tracks and communicates source data changes, monitors and maintains the shared content, and addresses support needs. This particular role is vital if your organization is undertaking any sort of data self-service initiative.
Acceptance Checking
This item addresses the issues that are common in the world of electronic data sharing: inconsistency, change, and error. Acceptance checking is a quality control process that reviews the data prior to distribution to confirm that it matches a set of criteria to ensure that all downstream users receive content as they expect. This item is likely the easiest of all details to implement given the power of existing data quality and data profiling tools. Unfortunately, it rarely receives attention because of most organization’s limited experience with data quality technology.
Data Audience
In order to succeed in any sort of data sharing initiative, whether in supporting other developers or an enterprise data self-service initiative, it’s important to identify the audience that will be supported. This is often the facet to consider first, and it’s valuable to align the audience with the timeframe of data sharing support. It’s fairly common to focus on delivering data sharing for developers support first followed by technical users and then the large audience of business users.
In the era of “data is a business asset” , data sharing isn’t a courtesy, it’s an obligation. Data sharing shouldn’t occur at the convenience of the data producer, it should be packaged and made available for the ease of the user.
Data Strategy Component: Identify
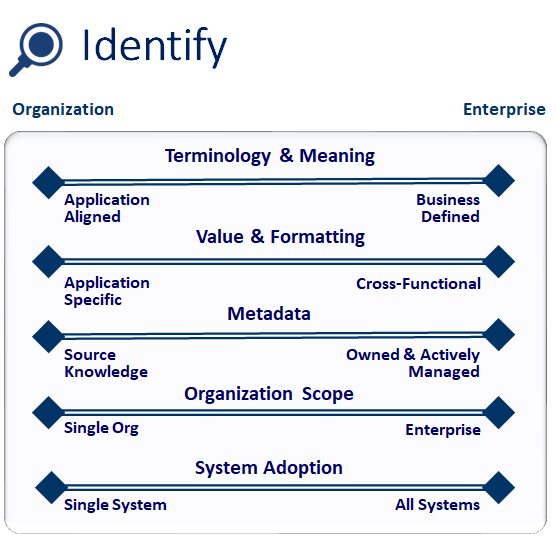
Based on the feedback and questions I’ve received on last week’s blog, “The 5 Components of a Data Strategy”, I thought I’d spend a bit more time discussing the individual components along with some of their associated details (or facets). I’ll review each of the five components over the next few weeks. This week, I’ll focus on Identify.
The definition of Identify is:
“The ability to identify data and understand its meaning regardless of its structure, origin, or location”
Identify encompasses how you reference and represent a particular piece of information. This component is probably the most fundamental component of all 5. If you don’t know what something is called, how can you use it, reference it, analyze it, or even share it?
You’ll notice 5 facets (or subcomponents) in the illustration associated with the Identify component (technology & meaning, value & formatting, metadata, organization scope, and system adoption). These facets provide a lower level of detail to analyze and address the specific needs of your environment and the associated Data Strategy. It’s not uncommon to have more than 5 core facets; facet identification is based on the quantity and details of your data strategy goals. I’ve identified 5 of the most common facets that I’ve seen while working with clients.
In addressing the data needs and challenges that exist in your environment, it’s valuable to understand if the ultimate solution requires an enterprise approach or can be addressed with an organizationally-centric approach. An organizational approach focuses on the terminology and details specific to an individual organization and assumes that the data isn’t shared or distributed outside the boundaries of an organization. An enterprise approach assumes that data is distributed across multiple organizations, so the rigor and effort involved is more time-consuming and complex. Part of developing a Data Strategy is to understand the level of sophistication necessary to share data across the appropriate audiences.
Terminology & Meaning
This is the most common challenge with data usage in companies. Are business terms used consistently, or do staff members (and reports) refer to business information with different names? The objective is to establish consistent business terminology for the audience that shares the information. It’s also important to be able to differentiate business concepts that use the same term, but have a different meaning.
Value & Formatting
This facet is the simplest, the most frequently ignored, and (I think) the most aggravating. The idea is to establish the format of a business term’s values. A simple example is identifying the state value in an address. Is the value represented as the 2-character abbreviation or the full name (or the ANSI code)? While not complicated, this facet can present an enormous obstacle in using data if such details are not well understood.
Metadata
Metadata is descriptive information about data (e.g. definition, source of creation, date of creation, valid values, etc.) In the world of business information, everyone agrees that metadata content is critical to using and sharing information. Does your company create, collect, and/or publish metadata about business information? The goal of metadata is not about building exhaustive, perfect, and up-to-date content, it’s about identifying what’s necessary to support usage and sharing (in a practical and time effective manner).
Organization Scope
This facet focuses on the breadth of audience that is associated with the Data Strategy. Does your company require organizations to share data, or is the disparity of operations prevent the need for sharing and distributing data across the enterprise? Organization scope identifies the different organizations that will become stakeholders and participants in the Data Strategy effort.
System Adoption
This facet is often neglected because there’s an assumption that all systems should any new rules and policies. While forcing all systems to adopt new data standards seems appropriate, it may be unrealistic in practice. If your company’s core application systems are packaged applications, there may be limitations to changing code to reflect standard names, terms, and values. You might find that your Data Strategy recommendations are applicable to all systems, or be limited to shared data sets and reporting data repositories.
To be fair, there are other characteristics that can be associated with this component; I’ve just identified 5 of the most popular. When I work with clients, it’s not uncommon to identify 10 or more characteristics of a component. It’s really about identifying the core characteristics (aspects) that are causing obstacles within your business environment and deciding which ones to focus on and improve.
